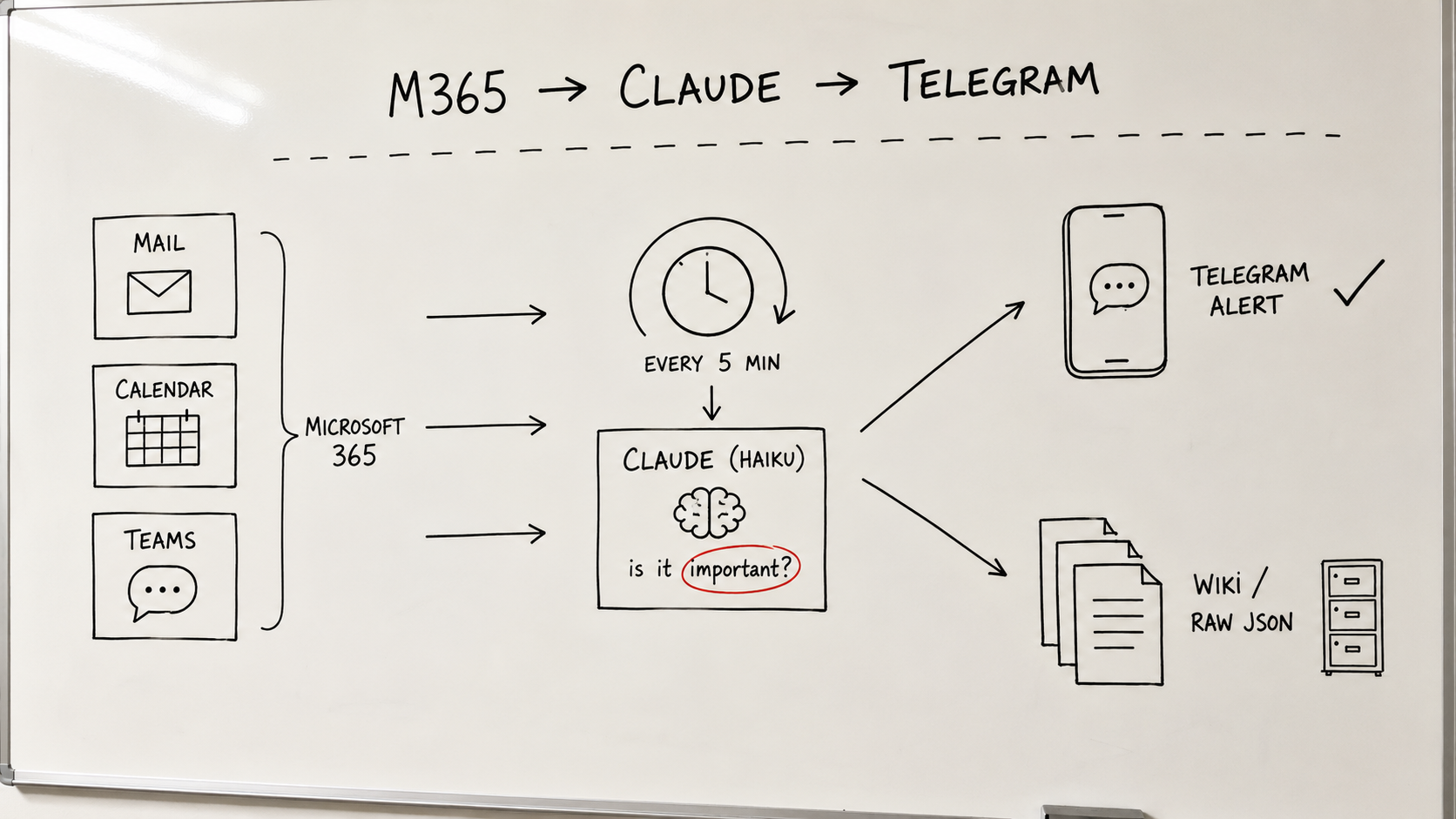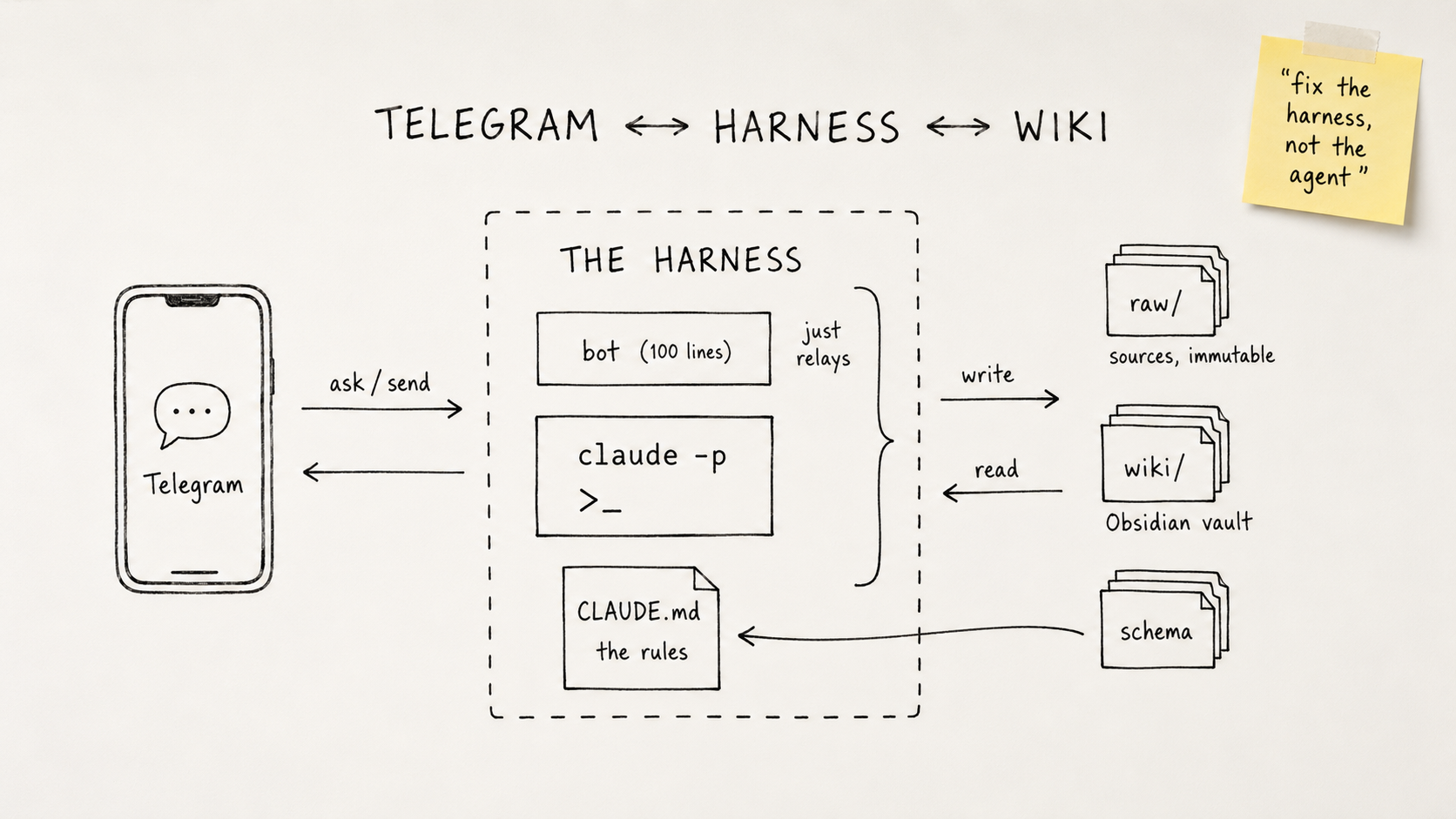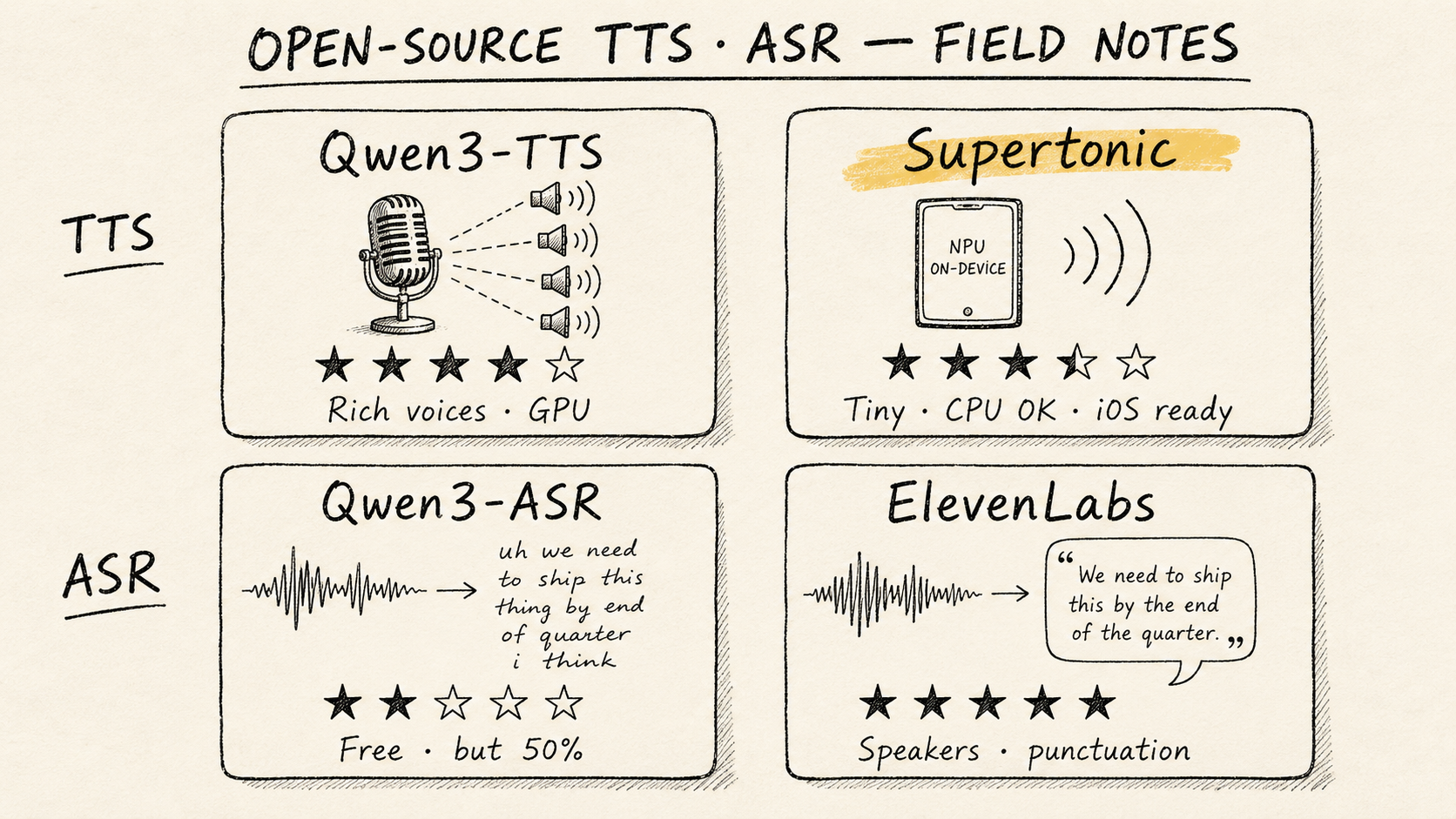
오픈소스 TTS·ASR 직접 굴려봤다 — Qwen, Supertonic, 그리고 ElevenLabs와의 거리
한국어 TTS·ASR 오픈소스를 한 바퀴 돌려봤다. TTS는 Qwen3-TTS와 Supertonic이 쓸 만했고 Qwen이 미세하게 앞섰지만, Supertonic의 Swift 지원으로 iOS on-device 가능성이 더 끌렸다. ASR은 Qwen3-ASR-1.7B만 직접 굴려봤는데 ElevenLabs 대비 50% 수준. 회의록은 아직 어렵지만 무료라는 점에 만족.